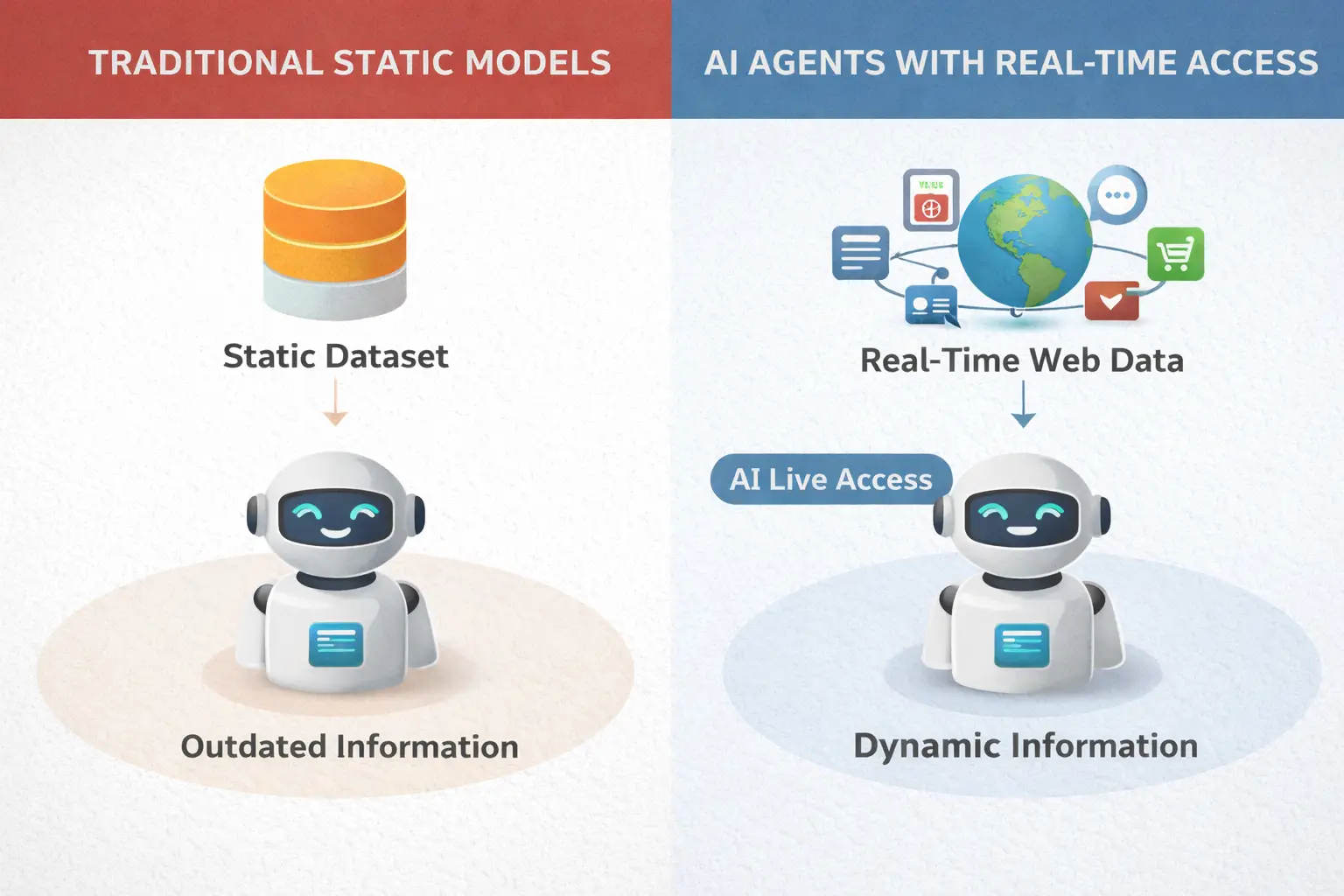
In 2026, the biggest limitation of artificial intelligence is no longer processing power—it’s outdated information. Traditional AI models were trained on static datasets that freeze knowledge at a specific point in time. That approach worked for answering general questions, but it falls short in a world where prices change hourly, trends shift daily, and breaking news reshapes decisions in minutes. This is where real-time web data becomes essential for modern AI agents.
Today’s AI systems are no longer just chatbots that summarize old information. They are becoming active, task-oriented systems that browse the web, monitor sources, compare data, and act on fresh inputs. From tracking stock prices and product availability to monitoring social media sentiment and breaking news, AI with live web access can deliver answers that reflect what’s happening right now, not last year.
The growth of real-time access is not just a feature upgrade—it’s a structural shift. In 2026, more businesses rely on AI agents to support customer service, market research, competitive analysis, and operational decisions. These agents continuously pull data from websites, APIs, news feeds, and platforms, turning the web into a live knowledge layer instead of a static library. Industry reports already show a sharp rise in AI systems integrated with browsing, scraping, and real-time data pipelines, and that adoption curve is still climbing.
Why does this matter? Because relevance, accuracy, and trust now depend on freshness. An AI agent that can see today’s prices, today’s reviews, and today’s headlines is fundamentally more useful than one that can’t. Real-time web data closes the gap between AI reasoning and real-world conditions, enabling faster decisions, better recommendations, and more reliable automation.
In this guide, you’ll learn what AI agents are, how they connect to live web data, which technologies make this possible in 2026, and why real-time access is becoming a core requirement for modern AI systems—not just a bonus feature.
What Are AI Agents?

AI agents are software systems designed to perceive, plan, and act in order to achieve specific goals, often with minimal human intervention. Unlike traditional AI tools that simply respond to prompts, AI agents can break tasks into steps, decide what actions to take, interact with tools or the internet, and adjust their behavior based on results. This shift turns AI from a passive assistant into an active problem-solver.
To understand the difference, think of a standard language model as a very smart text engine: you ask a question, it generates an answer based on its training data. An autonomous AI agent, on the other hand, can decide how to find the answer. It might search the web, open multiple sources, extract relevant data, compare results, and then present a conclusion. In other words, it doesn’t just respond—it executes a process.
In 2026, many internet-connected AI models already work this way. Browser-based agents can navigate websites, fill out forms, scrape data, and monitor changes over time. Tools like Claude in Chrome and similar browser-integrated agents can read live pages, summarize articles, compare products, and track updates across multiple tabs. Other AI agents operate in the background, watching price changes, checking availability, or monitoring mentions of a brand across the web.
A key feature of AI agents is autonomy with guardrails. They typically follow a loop:
- Understand the goal (for example, “find the best current price for this product”)
- Plan the steps needed (search, compare, verify)
- Execute actions (browse, extract data, analyze)
- Evaluate results and refine the approach if needed
This makes them fundamentally different from traditional chat interfaces, which rely entirely on the user to guide every step.
Another important distinction is tool use. Modern AI agents don’t live in isolation—they connect to browsers, APIs, databases, spreadsheets, and other software systems. This is what allows them to work with real-time web data instead of relying only on pre-trained knowledge.
In practical terms, AI agents are already being used for market research, competitive intelligence, customer support automation, content monitoring, and operations analysis. As their ability to access live information improves, they are becoming less like “smart chatbots” and more like digital workers that can observe the web, take action, and deliver up-to-date results on demand.
Why Real-Time Web Data Matters
In 2026, the value of AI is tightly linked to how current its information is. Models trained on static datasets will always lag behind reality, no matter how advanced their reasoning abilities are. This is why real-time web data has become a core requirement for modern AI agents rather than an optional upgrade.
The web changes constantly. News breaks every minute, product prices fluctuate, stock markets move in real time, and public sentiment shifts across social platforms throughout the day. An AI system that relies only on historical training data can easily provide answers that are outdated, incomplete, or simply wrong. In contrast, live web access for AI allows agents to verify facts, check the latest sources, and respond with up-to-date information that reflects current conditions.
Accuracy is the most obvious benefit. When an AI agent can read today’s headlines, check current exchange rates, or pull the latest earnings report, its responses become immediately more reliable. This is critical in use cases like financial analysis, market research, travel planning, and e-commerce, where even small timing differences can change decisions. For example, an AI helping a user track stocks or cryptocurrencies must work with live prices, not yesterday’s closing numbers.
Relevance is just as important. Search intent in 2026 is often time-sensitive: users want to know what’s happening now, what’s trending today, or what has just changed. AI agents with real-time access can adapt their answers to current events, seasonal shifts, and breaking developments, making their outputs far more useful than static summaries.
Developers and AI platform builders consistently point to live data as a key factor in agent performance. Without it, even the smartest agent is limited to educated guesses based on the past. With it, agents can validate claims, cross-check sources, and update their conclusions dynamically. This is especially important for tasks like fact-checking, monitoring competitors, tracking inventory, or watching for regulatory updates.
In short, real-time web data turns AI from a “knowledge snapshot” into a living system. It bridges the gap between reasoning and reality, ensuring that AI agents in 2026 don’t just sound smart—but stay correct, relevant, and trustworthy in a fast-moving digital world.
How AI Agents Actually Access Real-Time Web Data
AI agents don’t magically “know” what’s happening on the internet. They rely on a combination of data collection methods, infrastructure, and retrieval systems to continuously pull real-time AI Data into their workflows. In 2026, this process is far more structured and scalable than simple browsing.
The first layer is data acquisition. There are two main approaches: live APIs and web scraping. APIs provide structured, official access to data from platforms like financial markets, social networks, weather services, or e-commerce systems. They are fast and reliable, but limited to whatever the provider chooses to expose. Web scraping and crawling, on the other hand, allow AI agents to collect data directly from websites—news articles, product listings, reviews, forums, and more—making them far more flexible and comprehensive.
However, large-scale scraping brings technical challenges. Websites often limit or block automated traffic, which is why modern AI systems use proxies and rotating IPs to distribute requests across many addresses. This helps avoid rate limits, reduce blocking, and simulate natural browsing behavior. Bot management techniques—such as request pacing, header rotation, and fingerprint randomization—are also used to keep data collection stable and compliant with site policies. In practice, this infrastructure allows agents to monitor hundreds or thousands of pages in near real time without being shut down.
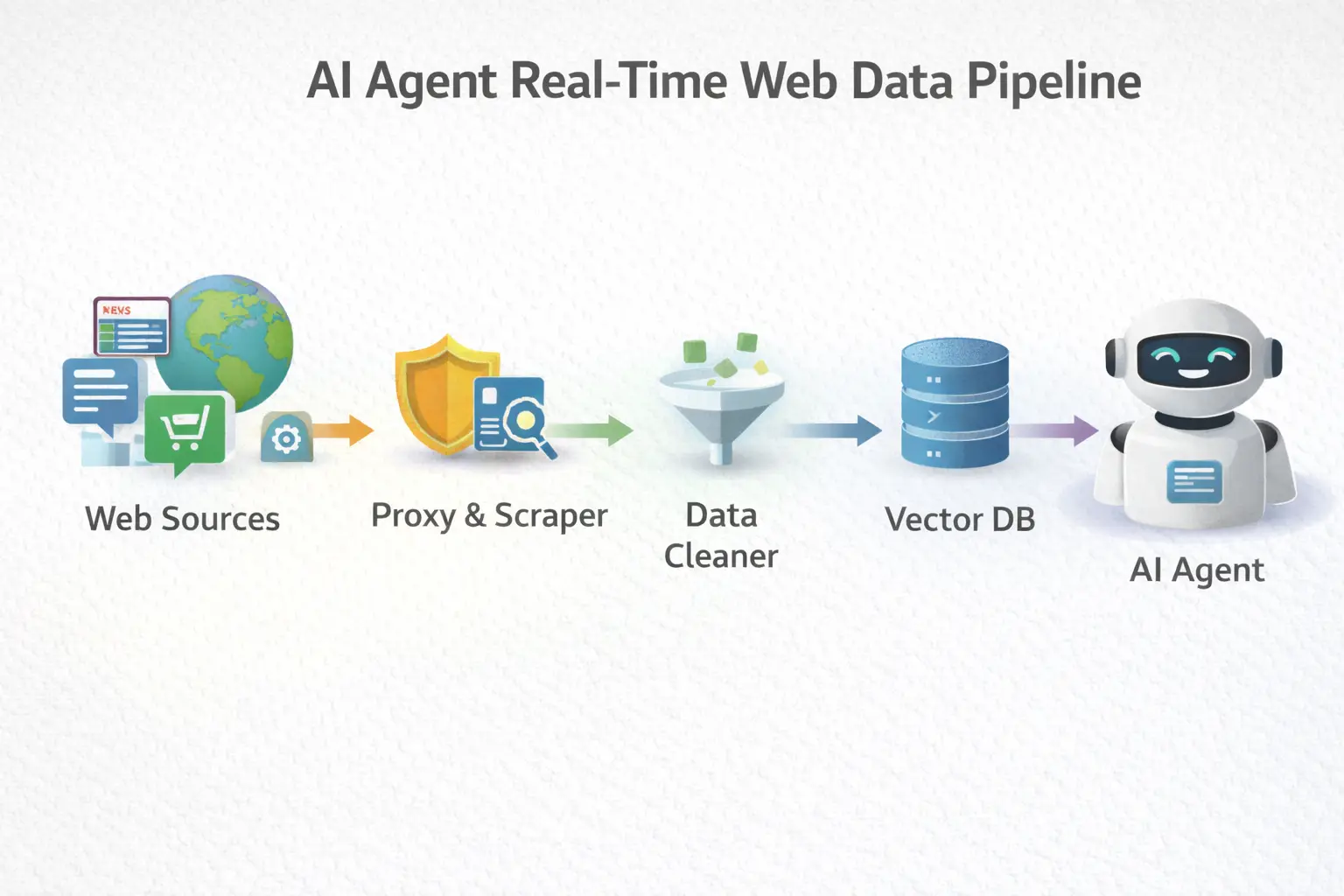
Once data is collected, it needs to be made usable by the AI model. This is where RAG (Retrieval-Augmented Generation) comes in. Instead of relying only on what the model learned during training, a RAG pipeline pulls fresh information from external sources and injects it into the model’s context at query time. The workflow typically looks like this: new data is scraped or fetched, processed and cleaned, embedded into vectors, and stored in a vector database. When a user asks a question, the system retrieves the most relevant, up-to-date chunks and feeds them to the model before it generates an answer.
This approach solves a core problem: keeping AI responses current without retraining the entire model. By continuously updating the vector database, AI agents can work with news from minutes ago, price changes from seconds ago, or newly published documents from today.
In modern architectures, real-time data ingestion is often handled by streaming pipelines. These pipelines watch sources, detect changes, and push updates through processing layers automatically. For example, an AI agent tracking competitor prices might scrape product pages every hour, update embeddings, and immediately reflect changes in its recommendations.
Put together, web scraping, APIs, proxies, RAG pipelines, and vector databases form the backbone of how AI agents in 2026 access and use real-time web data. The result is a system that doesn’t just think—it stays connected to the live internet and reasons with information that’s actually current.
Technologies Empowering Live Web Access
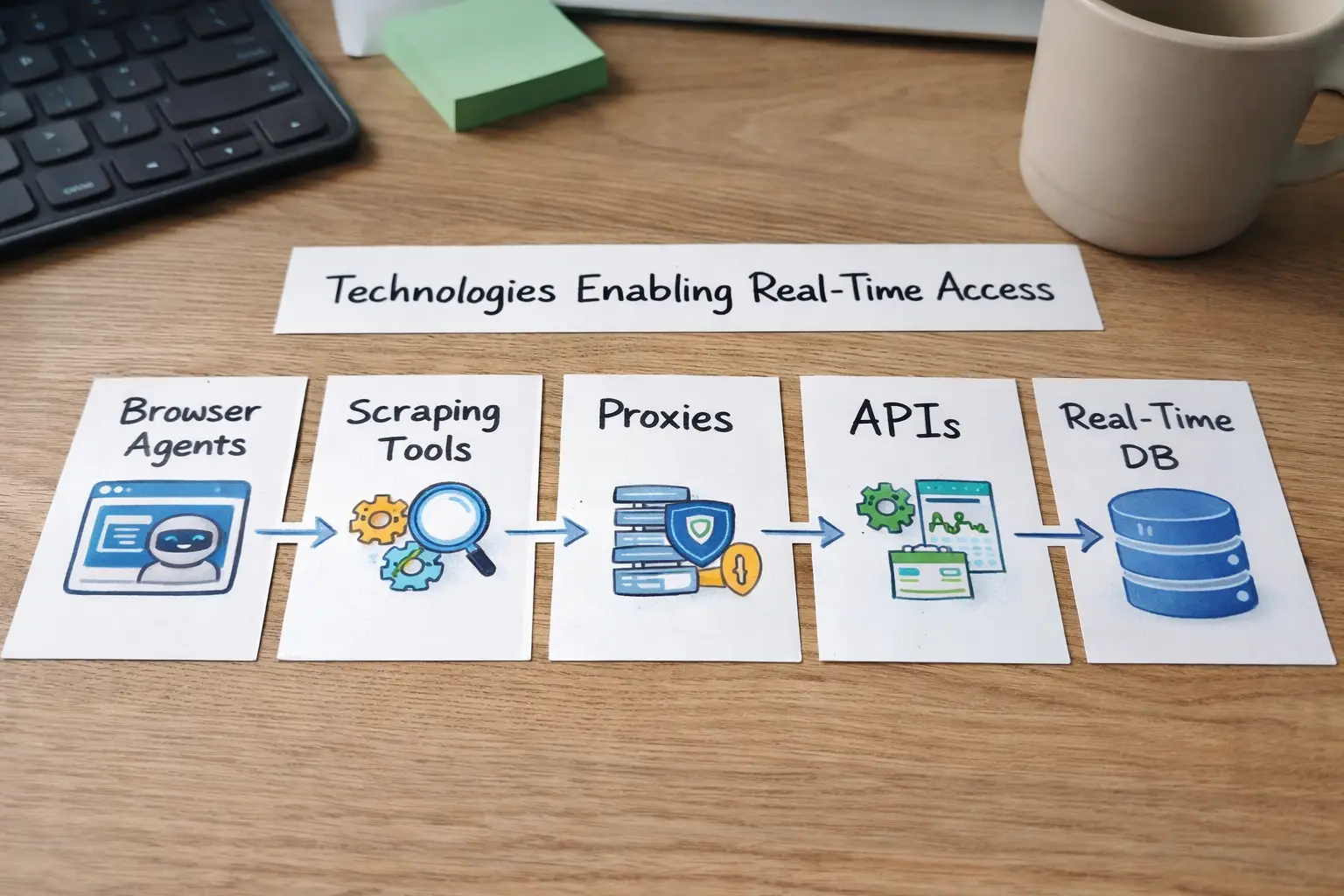
Behind every AI agent that works with real-time web data is a stack of technologies designed to fetch, process, and deliver live information reliably. In 2026, this stack has matured into a combination of browser automation, web scraping tools, proxy infrastructure, and data ingestion systems that work together to keep AI models connected to the live internet.
At the front of this stack are browser automation frameworks and agent-oriented tools. Solutions like Browser Use, Crawl4AI, and similar libraries allow AI agents to interact with websites much like a human user would—opening pages, clicking buttons, filling forms, scrolling, and extracting content. This is essential for sites that rely heavily on JavaScript or dynamic loading, where simple HTTP requests are no longer enough. For AI agents, browser automation turns the web into an interactive environment rather than a static collection of pages.
Next come web scraping APIs and crawling frameworks. These tools handle large-scale data collection across thousands or even millions of URLs. They manage scheduling, retries, parsing, and content extraction, transforming raw HTML into structured data that AI systems can use. Modern scraping platforms are built with scalability in mind, supporting continuous monitoring of news sites, e-commerce stores, forums, and documentation portals.
To make this work at scale, AI systems rely heavily on proxies for AI and anti-bot evasion layers. Proxy networks distribute requests across many IP addresses and regions, reducing the risk of blocking and rate limiting. On top of that, bot management techniques—such as user-agent rotation, request pacing, and fingerprint randomization—help keep data pipelines stable. Without this layer, even the best scraping or automation tools would fail quickly under real-world conditions.
Another important piece is APIs and emerging standards that expose web content in more machine-friendly ways. In 2026, initiatives like MCP-style protocols and projects such as NLWeb aim to make websites easier for AI agents to read and query directly. Instead of scraping unstructured pages, agents can increasingly consume structured endpoints designed for programmatic access, improving reliability, speed, and compliance.
Finally, all of this feeds into data ingestion pipelines. These pipelines clean, normalize, and enrich incoming data before storing it in databases or vector stores for retrieval. Structured data formats, schema markup, and AI-ready interfaces play a critical role here. When content is well-structured, AI agents can understand it faster, retrieve it more accurately, and use it more effectively in reasoning and generation tasks.
Together, browser automation, scraping tools, proxy infrastructure, APIs, and ingestion systems form the backbone of live web access for AI. They turn the chaotic, constantly changing internet into a usable, real-time knowledge source for intelligent agents.
Use Cases: What Real-Time Data Enables

When AI systems gain live web access, their role shifts from passive assistants to active, decision-support agents. Real-time web data applications are now central to how businesses, analysts, and developers use AI in 2026. Below are some of the most impactful use cases where up-to-date information makes a measurable difference.
1. Search and Answer Generation (Live News & Trends)
Traditional search-based answers often rely on indexed pages that may be hours or days old. AI with live web access can scan breaking news, trending topics, and freshly published content to generate answers that reflect what is happening right now. This is especially valuable for journalists, researchers, and content teams tracking fast-moving stories. For example, an AI agent can summarize today’s top developments in a specific industry, compare multiple live sources, and highlight changes as they happen—something static models simply cannot do.
2. Financial Insights and Trading Signals
Financial markets are one of the clearest examples of why real-time data matters. Prices, volumes, and sentiment change by the second. AI agents connected to live market feeds, news sites, and social platforms can monitor earnings reports, macroeconomic announcements, and breaking headlines in real time. This allows them to flag anomalies, detect early signals, and support faster decision-making. While human oversight is still essential, AI systems can dramatically reduce the time between an event and a response.
3. Market Research and Competitive Analysis
For marketers and strategists, staying updated on competitors is critical. AI agents can continuously track competitor websites, pricing pages, product updates, job postings, reviews, and press mentions. With real-time web data, they can alert teams when a competitor launches a new feature, changes pricing, or shifts messaging. This turns market research from a periodic activity into a continuous, automated process driven by live information.
4. E-commerce and Price Monitoring
In e-commerce, prices and availability change frequently across platforms and regions. AI agents with live access can monitor product listings, stock levels, discounts, and shipping conditions across multiple stores. This enables dynamic pricing strategies, faster reaction to competitors, and better purchasing decisions. For consumers, it means smarter shopping assistants that can check current deals instead of relying on outdated listings.
5. Customer Support with Real-Time Context
Customer support is increasingly powered by AI, but static knowledge bases are often the weakest link. With real-time web data, support agents can check current service statuses, known issues, policy updates, or recent announcements before responding. For example, if a service outage is reported minutes ago, an AI agent can incorporate that context into its replies immediately, reducing frustration and improving trust.
Across all these scenarios, the pattern is the same: AI with live web access is more accurate, more relevant, and more useful. Real-time data turns AI from a reactive tool into a proactive system that can monitor, analyze, and respond to the world as it changes.
Challenges and Ethical Considerations
As AI agents increasingly rely on real-time web data, they also face a growing set of technical, legal, and ethical challenges. Accessing the live internet at scale is not just an engineering problem—it requires careful consideration of web scraping ethics, bot detection, and privacy concerns.
One of the most immediate technical barriers is bot blockers and CAPTCHAs. Many websites deploy advanced detection systems to protect their infrastructure, content, and users. These systems analyze traffic patterns, browser fingerprints, and behavior signals to distinguish humans from automated agents. While this is necessary for security, it creates friction for legitimate AI use cases such as research, accessibility tools, and monitoring. For developers, the challenge is to design agents that behave responsibly, respect rate limits, and avoid creating unnecessary load on websites.
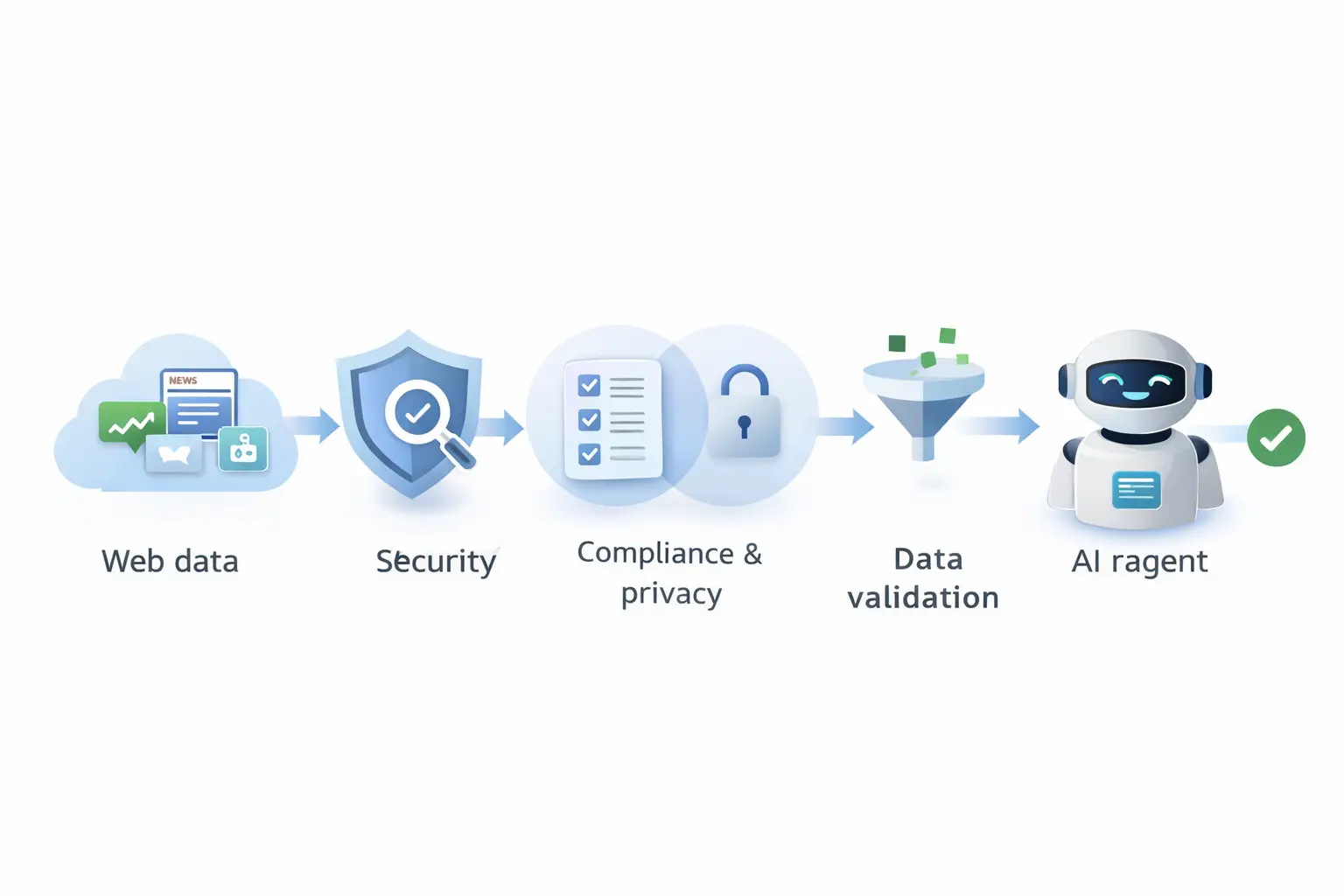
Legal and policy constraints add another layer of complexity. Websites often define acceptable access in their robots.txt files, terms of service, and usage policies. Ignoring these rules can lead to legal disputes, blocked access, or reputational damage. Beyond site-specific policies, data protection regulations in many regions restrict how personal or sensitive data can be collected and processed. This makes privacy concerns central to any system that gathers live web information. Even when data is publicly available, how it is stored, combined, and used by AI systems matters.
Another major risk is data integrity and model hallucination. Real-time web data is noisy, inconsistent, and sometimes misleading. If an AI agent pulls inaccurate or low-quality information, it can amplify errors or generate confident but incorrect outputs. This is especially dangerous in areas like finance, health, or legal information. Maintaining quality requires validation layers, source ranking, cross-checking, and human oversight in critical workflows.
Finally, there is the broader ethical question of balancing real-time access with respect for site policies and ecosystems. The web works because publishers, platforms, and users all have incentives to participate. If AI agents extract value without respecting boundaries, it risks undermining that balance. Sustainable systems are those that combine technical capability with transparency, compliance, and restraint.
In short, the future of AI agents with live web access depends not only on what is possible, but on what is responsible. Solving these challenges is essential for building systems that are both powerful and trustworthy.
The Future of Live Web Data & AI Agents
Looking ahead to 2026 and beyond, the future of AI agents is tightly linked to the evolution of real-time web data trends. As AI systems become more autonomous, their dependence on live, up-to-date information will only increase. Static training data will remain important, but it will no longer be enough for agents expected to plan, act, and adapt in dynamic environments.
One major shift will be the deeper integration of AI agents into everyday applications. Productivity tools, browsers, customer support systems, and business dashboards are already moving toward agent-driven workflows. In the coming years, these agents will not just answer questions—they will monitor markets, track competitors, manage tasks, and respond to events as they happen, all powered by continuous access to the live web.

We will also see improvements in how the web itself is exposed to machines. More platforms are likely to offer structured, AI-friendly interfaces, reducing reliance on brittle scraping and making data access more reliable and transparent. At the same time, standards around data usage, attribution, and access control will become more important as the volume of AI-driven traffic grows.
Another key trend is the tighter coupling between real-time data pipelines and reasoning systems. Instead of treating retrieval as a separate step, future agents will blend search, ingestion, and decision-making into a single loop. This will allow them to update their understanding continuously, adjust plans on the fly, and operate with a level of situational awareness that was not possible before.
Ultimately, the link between live web data and AI growth is straightforward: the more current and connected an AI system is, the more useful it becomes. The next generation of AI agents will not just know about the world—they will observe it in real time and act within it. That shift will define how AI moves from helpful tools to truly adaptive digital collaborators.
Conclusion
As AI agents continue to evolve, one thing is becoming clear: real-time web data is no longer optional—it is essential. From answering time-sensitive questions to monitoring markets, tracking competitors, and executing dynamic tasks, modern AI systems depend on live information to stay accurate, relevant, and useful. Static training data can provide a foundation, but it cannot keep pace with a world that changes by the minute.
Throughout this guide, we’ve explored how AI agents access live web data, the technologies that make it possible, the real-world use cases driving adoption, and the challenges that come with operating at scale. We’ve also seen how ethical access, data quality, and compliance are just as important as speed and coverage. The future of AI agents will be shaped not only by better models, but by better data pipelines and smarter ways to connect AI systems to the real world.
In practice, this means organizations need reliable infrastructure for collecting, managing, and validating web data in real time. Platforms that provide global proxy networks, scalable data collection tools, and compliance-focused access layers fit naturally into this ecosystem by enabling fresh, large-scale web data to be gathered responsibly and efficiently. As AI agents become more autonomous and more embedded in daily workflows, the ability to tap into accurate, up-to-date web information will become a key differentiator between systems that merely respond—and those that truly understand and act.